2022. 6. 16. 08:49ㆍVulkan
개요
셰이더 프로그램에는 한 번의 그리기 명령의 모든 실행(invocation)에 대하여 공유되는 uniform이라는 변수가 있습니다. 주로 선형 공간에서의 변환을 주거나 조건, 샘플러 등을 주는 용도가 있었죠.
GL에서는 glGetUniformLocation에 변수 이름을 넣어 얻어낸 위치를 저장해 두었다가 glUniform 계열 함수로 값을 지정했었는데요, 벌칸에서는 어떻게 할까요?
목차
2.1. 버퍼 준비하기
2.2. 기술자 집합
2.3. 파이프라인에서 기술자 집합 참조하기
2.4. std140
3. 푸시 상수
4. 버퍼 관리에 대하여
본문
1. 리소스 기술자(descriptor)
벌칸 사양에서 사실상 공유 버퍼란 이름이 가장 먼저 나오는 곳이 바로 14장, Resource Descriptors입니다. 이 디스크립터란 놈은 지금 배울 공유 버퍼에만 관련된 것은 아니므로 잠깐 이게 뭔지 알아보고 갑시다.
 |
렌더패스를 만들 때 첨부물의 사양을 결정하는 VkAttachmentDescription 배열과 서브패스에 대한 VkSubpassDescription 배열을 구성했었지. 그게 그건가? | |
| 사양을 읽어 보자. |  |
|
기술자는 버퍼, 버퍼 뷰, 이미지 뷰, 샘플러 등과 같은 셰이더 자원을 나타내는 불투명한 데이터입니다.
기술자는 명령 기록 동안 바인드되어, 이어지는 그리기 명령에 사용되는 기술자 집합으로 정리되어 있습니다.
즉 기술자는 셰이더가 있는 파이프라인으로 입력되는 데이터를 설명(기술)하고 그 데이터를 참조하는 것입니다. 더 직관적으로 설명하자면 다음을 셰이더가 참조한다고 생각하면 되겠습니다.
struct descriptorSet{
uniformBuffer descriptor0;
texture descriptor1;
storageBuffer descriptor2[4];
};
단적으로 말해 그때의 첨부물 기술자는 이 리소스 기술자와는 비슷합니다. 첨부물 기술자가 프레임버퍼의 첨부물의 호환 사양을 기술하여 프레임버퍼와 같이 바인드했었고, 리소스 기술자는 위와 같이 버퍼 등과 같은 자원의 사양을 기술하고 만들어진 자원을 바인드합니다. 서브패스는 그 자리에 파이프라인이 들어갔었죠.
기술자와 기술자 집합, 더하여 풀까지는 실습하면서 알아보도록 합시다.
2. 공유 버퍼를 위해 리소스 기술자 사용하기
2.1. 버퍼 준비하기
공유 버퍼를 준비하는 건 앞의 정점 버퍼를 준비하는 과정과 유사합니다. 다만, 앞으로 '스테이징'이라는 걸 하는 걸로 바꾼다고 했던 그때랑 달리 어연간해선 메모리 맵을 유지할 겁니다. 공유 버퍼의 값들은 자주 바뀌기 때문입니다. 일반적으로 카메라 성분에 해당하는 뷰/투영 행렬은 프레임당 1회, 객체를 논리적으로 배치하는 모델 행렬은 프레임당 물체 수만큼 설정되죠. 앞으로 모듈화 단계에 들어가면, 그러한 특징에 대하여 효율적인 기능을 사용할 겁니다.
정점 버퍼 때랑 마찬가지로 멤버를 일단 준비합니다. 지금은 정적변수지만 나중에 모듈화할 때 파이프라인과 합칠 겁니다. 그런데 과연 공유 버퍼는 몇 개나 필요할까요? 일반적인 용도를 생각해 볼 필요가 있습니다.
| 자, 직접 생각해 보는 게 좋을 거야. 우리가 명령 버퍼를 여러 개 굴리는 이유가 뭘까? | |
|
|
그리는 동안에 혹은 명령을 쓰는 동안에 또 다른 명령을 쓸 수 있어서겠지? 제출되었고 아직 실행 중인 명령 버퍼에는 다시 쓸 수 없으니까. 이른바 파이프라이닝 구현이지. | |
| 명령 버퍼를 여러 개 굴릴 때 주의할 사항은 뭐였지? | |
|
|
프레임버퍼로의 출력에 대한 순서 보장! | |
| 이 상태에서 여러 개의 객체를 그리는 걸 너라면 어떻게 구현할 거야? | |
|
|
프레임 처음에 렌더패스 시작시키고 버퍼에는 하나씩 그리게 해서 각각 제출할 것 같네? 투명도 같은 것 때문에 순서가 정해져야 한다면 의존성 체인을 만들어야겠지. | |
| 데이터는 공유 버퍼로 어떤 식으로 넘기지? | |
|
|
메모리 맵으로 할 거라며. 그러니까 CPU에서 어떤 주소 공간에 데이터를 쓰고 플러시되겠네. 아직 안 배웠지만 아마 파이프라인 레이아웃 info에서 그 부분을 참조하도록 기술자를 넘겨줄 것 같아. | |
| 만약 공유 버퍼가 한 개라면 어떻게 해야 공유 버퍼를 이미 보낸 명령에서 사용한 뒤에 수정하게 됨을 보장할 수 있을까? | |
|
|
공유 버퍼는 CPU가 작성하는 거니까 지금까지 사용법을 배운 것 중에는 펜스를 쓰거나 그래픽스 큐가 놀기를 기다리거나 밖에 없지? | |
| 공유 버퍼를 여러 개 쓴다면? | |
|
|
파이프라인에서 여러 개의 공유 버퍼를 참조하게 해서 그 버퍼를 쓰는 명령마다 하나씩 대응해서 바인드하게 하면 되지 않을까? 근데 그게 가능해? | |
| 그럼 벌칸의 공유 버퍼 객체는 몇 개를 만들어야 할까? | |
|
|
파이프라인 한 개당 명령 버퍼 수만큼! | |
| 다시 생각할 기회를 주지. | |
|
 |
으응? | |
조금만 더 나아가자면, 셰이더에서 공유 버퍼 객체를 몇 개 쓰냐에 따라 달라지겠죠. GL 때를 떠올려 보면, 원래 파이프라인에서는 공유 버퍼가 한 세트인 게 이치에 맞습니다. 그 때문에 모듈화하면 파이프라인에서 논리적 공유 버퍼 한 개로 여러 개의 공유 버퍼를 감싼 구조를 쓰게 될 겁니다. 하지만 지금 당장은 단순히 파이프라인이 한 개이며 공유 버퍼 객체도 한 개만 쓸 것이므로, 명령 버퍼 수만큼의 배열을 만들겠습니다.
vkCmdUpdateBuffer로 명령 버퍼 중에 원하는 버퍼를 (최대 65535바이트) 수정하도록 끼우는 것도 가능합니다. 이 경우, CPU와의 동기화는 없이 공유 버퍼 객체 한 개를 쓰는 게 가능하겠지만 메모리 장벽, 그리고 타 명령 버퍼와의 동기화가 필요하다는 점에 유의하세요. 혹자의 벤치마크에 따르면, memcpy가 더 빨랐다고 합니다(댓글을 내려가다 보면 있습니다). 더욱이 이 글도 참고해 보세요. [이 함수는 렌더패스가 진행되는 중에 사용할 수 없어 버퍼 클리어를 명시적 함수로 해야 합니다. 이는 사실상 벌칸 가지고 GL 아래 수준의 속도를 얻겠다는 말과 다름이 없게 됩니다.]
|
그럼 명령 버퍼 하나 해서 렌더패스 시작.. 하고 제출하고 그거 펜스로 기다리고 다른 버퍼 돌리고 최종적으로 끝내면 되는 건가? | |
| 주 명령 버퍼를 끝낼 때는 렌더패스가 살아 있으면 안 돼. 그러니 방법은, 보조 명령 버퍼에 기록한 걸 넘기면서 돌리거나 / 렌더패스를 시작할 때 색 버퍼 등을 클리어하지 않도록 하고, 다 그린 걸 표시 및 사용하고 나서 명시적으로 버퍼를 클리어하게 해서 매번 렌더패스 시작/끝을 명시하거나겠지. 전자의 문제점은 넘기는 버퍼가 '실행 가능' 혹은 '큐 대기' 상태여야 한다는 점으로, 파이프라인 구조를 제대로 살리려면 보조 명령 버퍼가 그리는 객체 수에 비례하게 필요하지 않겠어? |
|
|
버퍼 하나를 굴릴 때 굴리더라도 공유 버퍼의 값을 바꾸는 건 그릴 때 해야 하잖아요? 그걸 어떤 식으로 해야 할지는 아직 저도 모릅니다.
문제는 말이죠, 명시적 클리어는 일반적으로 렌더패스 시작 시의 클리어보다 성능이 나쁘다고 하네요. 하지만 이 메모리 맵 방식을 쓰려면 값을 쓰고 바로 그려야 하니까요. 지금 지식으로는 여러 버퍼를 반복적으로 돌리는 방식이 조금 어렵겠습니다. 일단은 기술자의 활용법에 대하여 먼저 알아봅시다.
일단 삼각형 하나만 그리는 현 상황에서는 공유 버퍼의 수를 명령 버퍼의 수와 같게 맞추는 게 맞습니다. 아니면 공간을 그만큼 할당하거나요. 이후 일반적인 상황에서 어떻게 해야 할지는 이후에 결정할게요.
하던 대로 멤버를 만들어 줍시다.
// VkPlayer.h
static VkBuffer ub[];
static VkDeviceMemory ubmem[];
static void* ubmap[];
// 공유 버퍼를 생성합니다.
static bool createUniformBuffer();
// 공유 버퍼를 해제합니다.
static void destroyUniformBuffer();이전에 파이프라인을 구성할 때 '파이프라인 레이아웃'은 그냥 존재만 확인하고 넘겼었죠. 여기에 기술자에 관한 정보가 들어가기 때문에, 이들을 비롯한 기술자의 초기화는 파이프라인 생성보다 이전이어야 합니다. 해제는 같은 이치로 그 역순으로 하면 되겠죠.
// VkPlayer::init()
...
&& createFramebuffers()
&& createUniformBuffer()
&& createPipelines()
...버퍼 생성과 해제는 정점 버퍼 때랑 완전히 같습니다. 설명은 생략합니다.
// VkPlayer.cpp
bool VkPlayer::createUniformBuffer() {
VkBufferCreateInfo info{};
info.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO;
info.usage = VK_BUFFER_USAGE_UNIFORM_BUFFER_BIT;
info.size = sizeof(float) * 16;
info.sharingMode = VK_SHARING_MODE_EXCLUSIVE;
for (int i = 0; i < COMMANDBUFFER_COUNT; i++) {
if (vkCreateBuffer(device, &info, nullptr, &ub[i]) != VK_SUCCESS) {
fprintf(stderr, "Failed to create fixed uniform buffer\n");
return false;
}
}
for (int i = 0; i < COMMANDBUFFER_COUNT; i++) {
VkMemoryRequirements mreq;
vkGetBufferMemoryRequirements(device, ub[i], &mreq);
VkMemoryAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_MEMORY_ALLOCATE_INFO;
allocInfo.allocationSize = mreq.size;
allocInfo.memoryTypeIndex = findMemorytype(mreq.memoryTypeBits, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, physicalDevice.card);
if (vkAllocateMemory(device, &allocInfo, nullptr, &ubmem[i]) != VK_SUCCESS) {
fprintf(stderr, "Failed to allocate memory for fixed ub\n");
return false;
}
if (vkMapMemory(device, ubmem[i], 0, info.size, 0, &ubmap[i]) != VK_SUCCESS) {
fprintf(stderr, "Failed to map to allocated memory\n");
return false;
}
if (vkBindBufferMemory(device, ub[i], ubmem[i], 0) != VK_SUCCESS) {
fprintf(stderr, "Failed to bind ub and memory\n");
return false;
}
}
return true;
}
void VkPlayer::destroyUniformBuffer() {
for (int i = 0; i < COMMANDBUFFER_COUNT; i++) {
vkFreeMemory(device, ubmem[i], nullptr);
vkDestroyBuffer(device, ub[i], nullptr);
}
}
2.2. 기술자 집합
기술자는 버퍼에 대한 설명을 포함하며 지금까지와 일맥상통하게 용도, 수 등에 대한 설명이 들어갑니다. 일단 기술자 집합을 만들어 봅시다.
일단 이 멤버를 만들고 생성해 줍니다. 집합을 관리할 풀을 만들고, 기술자 자체의 사양을 결정하는 레이아웃을 만들고, 풀에 레이아웃을 보여주고 할당하는 식입니다.
// VkPlayer.h
static VkDescriptorSetLayout ubds;
static VkDescriptorPool ubpool;
static VkDescriptorSet ubset[];
static bool createDescriptorSet();
static void destroyDescriptorSet();일단 레이아웃 생성을 위해서는 2개 구조체가 필요합니다. layoutBinding 구조체가 createInfo의 확장으로 보면 편하겠네요. 생소하지만 코드 자체를 보면 의미를 쉽게 알 수 있습니다. descriptorCount의 경우 한 집합 아래에 몇 개의 디스크립터가 들어가는지를 명시하며, 셰이더 상에서는 해당 원소의 배열로 참조됩니다. 이건 나중에 관절 애니메이션 구현할 때 다시 활용해 봅시다.
(22.8.7 추가)CreateInfo 구조체에서 여러 개의 바인딩을 넣는다면, 한 개의 기술자 집합을 할당할 때 여러 종류의 기술자를 동시에 할당하는 셈이 됩니다.
bool VkPlayer::createDescriptorSet() {
VkDescriptorSetLayoutBinding uboBinding{};
uboBinding.binding = 0; // 그냥 번호입니다. 셰이더에서 0번에 연결한다면 여기에 연결하는 겁니다.
uboBinding.descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
uboBinding.descriptorCount = 1;
uboBinding.stageFlags = VK_SHADER_STAGE_VERTEX_BIT; // VK_SHADER_STAGE_ALL_GRAPHICS
VkDescriptorSetLayoutCreateInfo info{};
info.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO;
info.bindingCount = 1;
info.pBindings = &uboBinding;
if (vkCreateDescriptorSetLayout(device, &info, nullptr, &ubds) != VK_SUCCESS) {
fprintf(stderr,"Failed to create descriptor set layout for uniform buffer\n");
return false;
}
return true;
}
void VkPlayer::destroyDescriptorSet() {
vkDestroyDescriptorPool(device, ubpool, nullptr);
vkDestroyDescriptorSetLayout(device, ubds, nullptr);
}기술자 풀의 경우 [타입과 할당할 기술자의 수]인 VkDescriptorPoolSize 배열을 주어 생성합니다. 여러 타입에 대하여 만들 수 있고, 풀 전체에서 생성할 수 있는 최대 수도 입력합니다. 여기선 한 종류만 쓸 것이기 때문에 maxSets에는 지금 만들 디스크립터 수를 주면 됩니다. 앞으로 다른 타입에 대한 기술자를 만든다면 여기서 수정하는 게 좋겠죠.
(22.8.7 수정) maxSets는 기술자 집합의 최대 할당 수입니다. 그리고 VkDescriptorPoolSize 구조체의 descriptorCount는 집합 한 개당이 아니라 모든 필요 할당 수입니다. 예를 들어 'A'타입 버퍼의 길이 4 배열을 가리키는 기술자 집합 2개를 할당하고자 한다면 저 자리에는 8 이상의 값이 들어가야 합니다. 기술자 집합에 바인딩이 여러 가지라면 당연히 해당 구조체를 그에 맞게 다 따로 정의해야 합니다.
짧게 말해 기술자 풀에서는 [최대로 할당할 수 있는 기술자 집합의 수]와 [타입별 할당할 최대 기술자 수]를 명시하게 됩니다.
이렇게 만들어 줍니다. (위 코드에 이어서)
VkDescriptorPoolSize size{};
size.type = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
size.descriptorCount = COMMANDBUFFER_COUNT;
VkDescriptorPoolCreateInfo dpinfo{};
dpinfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_POOL_CREATE_INFO;
dpinfo.poolSizeCount = 1;
dpinfo.pPoolSizes = &size;
dpinfo.maxSets = COMMANDBUFFER_COUNT;
if (vkCreateDescriptorPool(device, &dpinfo, nullptr, &ubpool) != VK_SUCCESS) {
fprintf(stderr,"Failed to create descriptor pool\n");
return false;
}그런데 이건 아직 버퍼와는 아무런 상관이 없죠. 기술자 풀 위에서 실제 기술자 집합을 만들고 나서 그 기술자가 참조하는 버퍼를 명시할 수 있습니다. 기술자 집합의 할당은 상기한 것처럼 풀 위에서 레이아웃을 주고 생성합니다. 개별 레이아웃마다 따로 생성하는 식이라 위에서 만든 레이아웃을 만들 수만큼 복제한 겁니다.
std::vector<VkDescriptorSetLayout> layouts(COMMANDBUFFER_COUNT, ubds);
VkDescriptorSetAllocateInfo setInfo{};
setInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_ALLOCATE_INFO;
setInfo.descriptorPool = ubpool;
setInfo.descriptorSetCount = COMMANDBUFFER_COUNT;
setInfo.pSetLayouts = layouts.data();
if (vkAllocateDescriptorSets(device, &setInfo, ubset) != VK_SUCCESS) {
fprintf(stderr,"Failed to allocate descriptor set\n");
return false;
}기술자 집합에서 값을 변경하려면 vkUpdateDescriptorSets 함수를 이용합니다. 여기를 통해 버퍼를 명시해 줍니다. 버퍼 정보에서 offset과 range 멤버를 통해 그 버퍼 내에서 어느 위치를 참조할지 결정합니다. binding의 경우 앞의 것과 같은 뜻이고 dstSet이 업데이트할 기술자 집합입니다. dstArrayElement은 VkDescriptorSetLayoutBinding에서 명시한 기술자 배열의 원소를 뜻합니다.
for (size_t i = 0; i < COMMANDBUFFER_COUNT; i++) {
VkDescriptorBufferInfo bufferInfo{};
bufferInfo.buffer = ub[i];
bufferInfo.offset = 0;
bufferInfo.range = sizeof(float) * 16;
VkWriteDescriptorSet descriptorWrite{};
descriptorWrite.sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
descriptorWrite.dstSet = ubset[i];
descriptorWrite.dstBinding = 0;
descriptorWrite.dstArrayElement = 0;
descriptorWrite.descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
descriptorWrite.descriptorCount = 1;
descriptorWrite.pBufferInfo = &bufferInfo;
vkUpdateDescriptorSets(device, 1, &descriptorWrite, 0, nullptr);
}해제는 명령 버퍼 때처럼 풀을 해제할 때 알아서 해 줍니다.
2.3. 파이프라인에서 기술자 집합 참조하기
이제 아까 할당한 공유 버퍼와 기술자 집합이 연결되었습니다. 이제 남은 건 버퍼에 값을 쓰는 것과 파이프라인에서 그걸 참조할 수 있도록 하는 겁니다.
파이프라인 생성 함수로 가서 레이아웃 생성을 이렇게 해 주세요. 방금 만든 setLayout만 추가하여 레이아웃의 사양만 알려줍니다.
VkPipelineLayoutCreateInfo pipelineLayoutInfo{};
pipelineLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
pipelineLayoutInfo.setLayoutCount = 1;
pipelineLayoutInfo.pSetLayouts = &ubds;
pipelineLayoutInfo.pushConstantRangeCount = 0;
pipelineLayoutInfo.pPushConstantRanges = nullptr;
vkCreatePipelineLayout(device, &pipelineLayoutInfo, nullptr, &pipelineLayout0);기술자 집합 바인드는 명령 버퍼에서 합니다. vkCmdDraw보다 전에만 하면 되겠습니다.
vkCmdBindDescriptorSets(commandBuffers[commandBufferNumber], VK_PIPELINE_BIND_POINT_GRAPHICS, pipelineLayout0, 0, 1, &ubset[commandBufferNumber], 0, nullptr);디스크립터 집합들을 바인드하는 것이므로 디스크립터 집합의 배열, 오프셋(시작 인덱스), 바인드할 개수를 넘깁니다. 마지막 2개는 동적 오프셋 수와 배열이 들어가는데, 이는 필요한 경우 나중에 설명하겠습니다.
값을 쓰는 건 아까 메모리 매핑을 했었죠. 그대로 작성만 하면 됩니다.
// VkPlayer::fixedDraw
...
vkWaitForFences(device, 1, &bufferFence[commandBufferNumber], VK_FALSE, UINT64_MAX);
vkResetFences(device, 1, &bufferFence[commandBufferNumber]);
vkResetCommandBuffer(commandBuffers[commandBufferNumber], 0);
float st = sinf(tp), ct = cosf(tp);
float asp = (float)swapchainExtent.height / swapchainExtent.width;
float rotation[16] = { // GLSL 셰이더에서 읽는 행렬은 열 우선 순서
ct*asp,st,0,0,
-st*asp,ct,0,0,
0,0,1,0,
0,0,0,1
};
memcpy(ubmap[commandBufferNumber], rotation, sizeof(rotation));
memcpy(ubmap[commandBufferNumber], rotation, sizeof(rotation));삼각형을 Z축 기준(=시계방향)으로 회전시킬 건데, 하는 김에 종횡비도 맞춥니다. 일단은 그런 것으로 알고 값을 그대로 넘기면 됩니다. 이것은 명령 버퍼 펜스가 발동한 후에 하면 참조가 확정적으로 끝났기 때문에 안전합니다.
|
근데 나는 열 우선 행렬을 저렇게 쓰면 실제 표기와 달라서 행 우선 행렬을 쓰는 게 더 편해. 어떻게 안 될까? | |
| 셰이더에서 벡터를 왼쪽에 곱해. 변환 여러 개를 적용하려면 적용 순서는 자연스럽게 좌에서 우가 되겠지? | |
|
컴파일하고 실행해 봅시다. 변화가 없지만 오류도 없어야 정상입니다. 변화가 없는 이유는 뻔하죠. 셰이더가 그대로니까요. 셰이더가 이 기술자 집합을 참조하게 uniform 변수를 만들어 줍니다.
layout(binding = 0) uniform UBO{mat4 rotation;} ubo;
void main() {
gl_Position = ubo.rotation * vec4(inPosition, 1.0);
fragColor = inColor;
}방금 binding=0으로 결정했으므로 ubo는 이제 0번에 바인드된 기술자 집합을 참조합니다. 한번 코드의 uboBinding.binding과 descriptorWrite.dstBinding 부분을 여기의 binding = 0과 함께 바꿔 보세요. 하나라도 어긋나면 확인계층에서 관련된 오류를 출력합니다.
이제 프로그램을 실행해 보면 이렇게 종횡비까지 맞춰져서 삼각형이 원점을 중심으로 시계 방향으로 돌고 있어야 합니다. (전에도 나왔었지만 파란 부분이 꼭대기점입니다.)
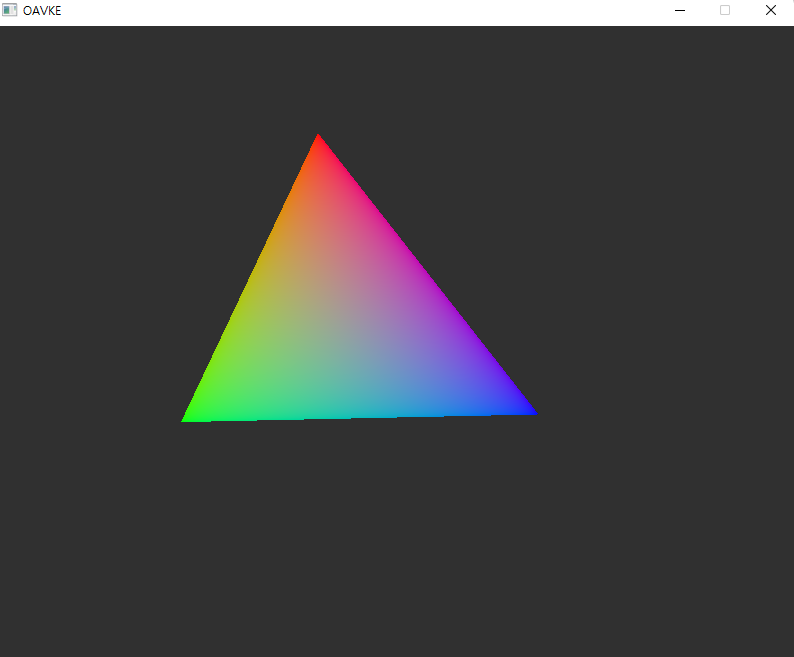
vkCmdBindDescriptorSets에서 여러 개의 집합을 바인드하는 경우 몇 번째 집합을 쓸지는 이렇게 명시하면 됩니다.
layout(set = 0, binding = 0) uniform UBO{mat4 rotation;} ubo;
참고로 어떤 그래픽카드에서도 동시에 바인드될 수 있도록 보장된 집합의 수는 4입니다. 예를 들어 동시에 텍스처를 3개 사용하고 싶은 경우 그 3개를 모두 포함한 (바인딩 넘버든 배열이든) 집합 한 개를 사용하는 것이 훨씬 안전합니다.
현재 0,1,2,3 집합이 바인드된 상태에서 1 위치에 다른 집합을 바인드하는 경우 0, 1만 남고 2,3은 무효화되는 점에 주의하세요.
2.4. std140
저렇게 C 구조체처럼 생긴 인터페이스 블록을 공유 버퍼 객체를 통해 쓰는 경우 CPU에서 (주로 memcpy로) 보내는 메모리 배열과 GPU에서 쓰는 메모리 배열을 통일할 필요가 있습니다. 몇 가지 규칙을 활용할 수 있는데, 기본적으로 구조체를 만들 때마다 질의하는 것보다는 통일된 규격을 쓰는 게 낫다는 입장도 많죠. 여기서는 std140이라는 규격을 소개해 봅니다. 규칙은 다음과 같습니다.
- 아래 설명은 벡터/행렬의 개별 성분(스칼라)이 N바이트짜리인 경우에 대한 것입니다.
- 기본 스칼라는 주소가 N의 배수여야 합니다.
- 2, 3, 4차원 벡터는 주소가 각각 2N, 4N, 4N의 배수여야 합니다.
- 배열은 앞 규칙에 따른 개별 성분 정렬에서 가까운 vec4의 베이스 정렬로 올림한 값입니다.
- 멤버가 R x C 열 우선 행렬인 경우 R차원 벡터가 C개 있는 배열과 같이 정렬합니다.
- 멤버가 R x C 열 우선 행렬의 S개짜리 배열일 경우 R차원 벡터가 S x C개 있는 배열과 같이 정렬합니다.
- 멤버가 R x C 행 우선 행렬인 경우 C차원 벡터가 R개 있는 배열과 같이 정렬합니다.
- 멤버가 R x C 행 우선 행렬의 S개짜리 배열일 경우 C차원 벡터가 S x R개 있는 배열과 같이 정렬합니다.
더 복잡한 내용은 별도의 자료를 찾아 보시기 바랍니다. 여기서는 자주 쓰이는 이 정도만 하도록 합니다.
template <class T, unsigned D>
struct UBentry {
alignas(sizeof(T)* (D <= 2 ? 2 : 4)) T entry[D];
T& operator[](size_t p) { return entry[p]; }
};
template <class T>
struct UBentry<T, 1> {
alignas(sizeof(T)) T value;
T& operator=(T v) { return value = v; }
};
using UBfloat = UBentry<float, 1>;
using UBint = UBentry<int, 1>;
using UBbool = UBentry<int, 1>;
using UBvec2 = UBentry<float, 2>;
using UBvec3 = UBentry<float, 3>;
using UBvec4 = UBentry<float, 4>;
using UBivec2 = UBentry<int, 2>;
using UBivec3 = UBentry<int, 3>;
using UBivec4 = UBentry<int, 4>;
using UBmat4 = UBentry<float, 16>;
// 용례
struct UBO{
UBmat4 model;
UBmat4 view;
UBmat4 proj;
UBfloat zoom;
};아무래도 다른 데서 memcpy를 통해 여기로 복사될 거니까요, 딱히 GLM 같은 것의 클래스 객체가 멤버로 들어갈 필요는 없을 것 같습니다. 꼭 다이렉트로 넣고 싶다면 위 코드를 조금만 변형하면 그만이겠죠. 구조가 바뀔 때마다 alignas를 넣는 것보다 직관적이긴 합니다.
vec2~vec4, ivec2~ivec4, int, float, mat4 말고 다른 타입을 쓸 거라면 사양을 보고 직접 연구를 해 보세요.
이러한 규칙을 쓰게 하려면 이런 식으로 공유 버퍼 블록에 std140이라고 표시하면 됩니다.
layout(std140, binding = 0) uniform UBO{mat4 rotation;} ubo;지금까지의 코드를 한번 구경해 볼까요?
3. 푸시 상수
푸시 상수는 위의 조잘조잘에서 나왔던 vkCmdUpdateBuffer랑 다르게 명령 버퍼에서 후속 명령이 들고 가는 uniform 값으로 보면 될 것 같습니다. 그런 만큼 메모리에 든 것보다는 빠르지만 명령 버퍼와 주기를 같이합니다. 그리고 파이프라인당 최대 한 개, 그리고 128바이트 이내로 정의하는 게 맞다고 봐도 무방합니다. (푸시 상수 범위의 한계의 가능한 최소치가 128바이트라고 명시됨) 상한값은 역시 그래픽 카드로부터 확인할 수 있지만, 이는 권장하지 않습니다. 푸시 상수 구조를 장치마다 달리 할 만한 기능이 있나요?
공유 버퍼를 만들 때는 버퍼 객체를 만들고 메모리를 할당하여 바인드했는데, 푸시 상수는 명령 버퍼에서 들고 가는 만큼 사양만 명시하고 나서 값을 주면 됩니다. 바로 확인해 봅시다.
createPipeline0 함수에서 VkPipelineLayoutCreateInfo를 구성할 때 공유 버퍼를 위한 기술자 집합 레이아웃을 넘겼는데, 그 옆에 있던 것이 pPushConstantRanges였습니다. VkPushConstantRange 타입인데, 참조 단계와 오프셋, 크기로 매우 단순합니다. 상기한 것과 같이 블록은 한 개만 가능하므로 offset은 그 블록 내에서의 오프셋을 말합니다.
// VkPlayer::createPipeline0
...
VkPushConstantRange pushRange{};
pushRange.offset = 0;
pushRange.size = 16;
pushRange.stageFlags = VK_SHADER_STAGE_FRAGMENT_BIT;
...
pipelineLayoutInfo.pushConstantRangeCount = 1;
pipelineLayoutInfo.pPushConstantRanges = &pushRange;
...offset과 size는 4의 배수여야 하며, 이는 아마 안 지키면 확인 계층에서 알아서 경고를 해 줄 겁니다. 데이터를 갖고 가는 것은 그리기 전에 명령 버퍼에서 다음과 같은 함수를 호출합니다.
float clr[4] = { 1.0f,0,0,1 };
vkCmdPushConstants(commandBuffers[commandBufferNumber], pipelineLayout0, VK_SHADER_STAGE_FRAGMENT_BIT, 0, 16, clr);매개변수는 명령 버퍼와 파이프라인 레이아웃, 참조 셰이더 단계, 오프셋, 데이터 크기, 데이터입니다.
아직 끝이 아닙니다. 조각 셰이더에서 이를 받을 공유 변수 집합을 만들고, 색상에 반영해 줍시다.
// tri.frag
layout(std140, push_constant) uniform ui{
vec4 color;
};
void main() {
outColor = color*vec4(fragColor, 1.0);
}
컴파일해서 실행하여 봅시다. 결과가 이렇게 나오면 됩니다.
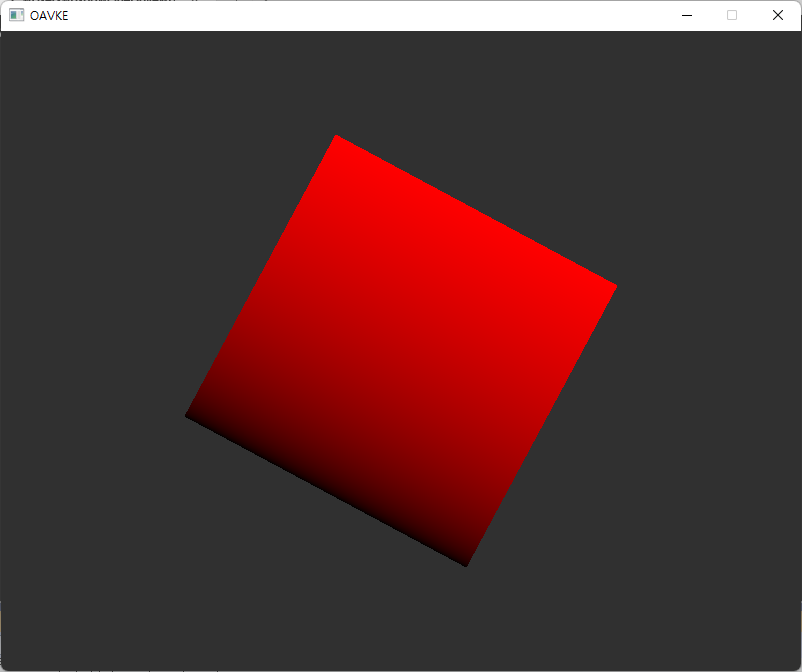
코드는 6번 글인 "깊이와 스텐실 버퍼" 이후에 반영된 것인 점 참고 바랍니다. 여기서 위와 같은 수정만 한 경우라면 사각형이 아니라 삼각형이 나오고 있을 텐데, 그게 맞겠죠. 거기서는 정점 버퍼와 인덱스 버퍼를 확장해서 사각형을 2개 그리고 있는데, drawCmd에서 이를 하는 만큼 푸시 상수를 다시 수정하는 것으로 별도의 동기화 처리 없이 이런 일이 가능하겠죠.
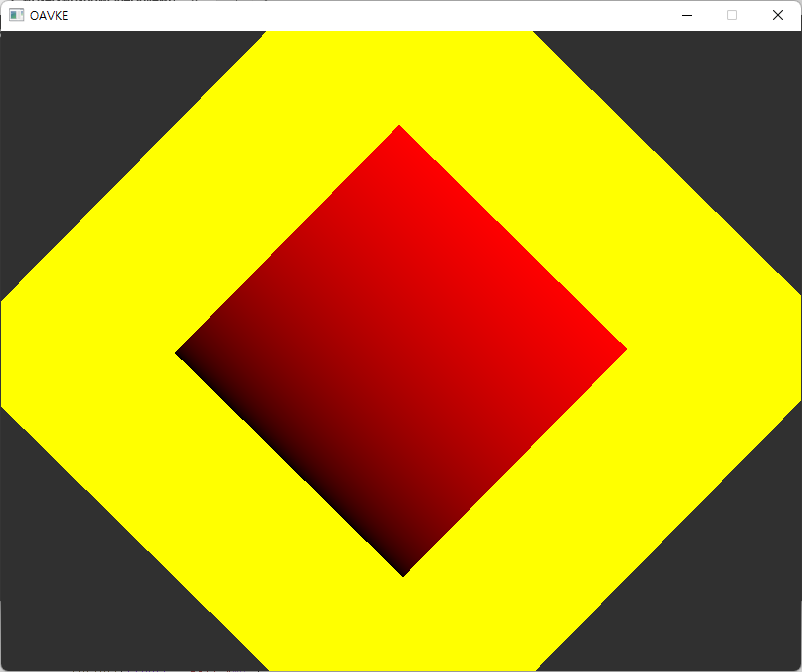
 |
오, 정말 유용한 기능인데? 이거라면 GL때처럼 동기화 걱정 없이 그냥 버퍼로 넘기면 되는 거 아냐? | |
| 그렇지. 푸시 상수를 이용하여 그리는 개별 객체마다 다르게 넘길 만한 공유 변수는 뭐가 있으려나? | |
|
|
모델 배치 행렬(64바이트), 기본 텍스처 샘플러 번호(4바이트), 법선맵 샘플러 번호(4바이트), 뭐, 2차원 게임을 만들려면 텍스처 좌표도 이동시켜야 할 거고(16바이트).. 위와 같이 섞을 색상도 있으면 좋겠네(16바이트). 뷰/투영 행렬 이나 광원 위치 같은 건 프레임당 한 번만 갈면 되니까 공유 버퍼 쓰면 되겠지. 하지만 관절 애니메이션 골격 같은 건 대체로 수천 바이트는 필요하고 그리는 객체별로 필요한데, 어쩔지 모르겠네. |
|
| 11편에서 다루겠다. 이거랑 이거 보면서 기다려. | |
|
4. 버퍼 관리에 대하여
GL에서 조금 더 배워 보신 분들이라면 메모리 할당 수에는 한계가 있다는 것을 알고 계실 겁니다. 이는 그래픽 카드에서 관리하는 메모리 상의 문제로, 임의의 객체를 그리고자 하여 임의의 수의 버퍼를 할당하고자 한다면 그 대신 하나의 버퍼를 할당하여 오프셋 여러 개로 참조하는 게 좋을 겁니다. 최대 버퍼 수는 이렇게 알아볼 수 있습니다.
vkGetPhysicalDeviceProperties(cards[i], &properties);
printf("maximum %d buffers\n",properties.limits.maxMemoryAllocationCount);이것을 중재하는 라이브러리인 VulkanMemroyAllocator가 있는데, 아마 실무 수준에서 활용하고자 한다면 이걸 배우는 것도 좋을 겁니다. 나중에 제가 관심이 가면 다루도록 할게요.
요약
변환과 같은 uniform 변수가 필요할 때에는 버퍼를 만들고 그에 대한 기술자 집합을 만들어야 합니다. 기술자 집합은 기술자 풀 위에서 할당되어 메모리가 관리됩니다. 만들고 나면 파이프라인 생성 시 pipelineLayout에서 기술자 집합에 대한 레이아웃을 명시하며, 실 사용 시 바인드하면 됩니다.
한편 버퍼 메모리는 한 번의 큰 할당을 여러 구역으로 나누어 여러 목적으로 사용하는 것이 따로 할당하는 것보다 권장됩니다.
과제
여전히 삼각형 하나만 그릴 때 여러 명령 버퍼를 굴리는 이 상황에 대하여, 공유 버퍼를 한 개로 합치고 다른 오프셋 참조를 하도록 구현해 봅시다.
'Vulkan' 카테고리의 다른 글
| Vulkan - 6. 깊이와 스텐실 버퍼 (0) | 2022.06.21 |
|---|---|
| Vulkan - 5. 인덱스 버퍼와 스테이징 버퍼 (0) | 2022.06.21 |
| Vulkan - 3. 세마포어와 펜스 (0) | 2022.06.15 |
| Vulkan - 2. 안녕 삼각형 (0) | 2022.06.08 |
| Vulkan - 1. 벌칸의 특징, 그리고 시작을 위해 구성하기(Windows) (0) | 2022.06.08 |